A consolidated reference covering the full data stack — relational fundamentals, SQL practice, dimensional modeling, NoSQL and graph stores, ingestion and streaming pipelines, open lakehouse table formats, and modern vector databases for RAG and semantic search.
Language reference (SELECT, JOIN, window functions), query performance and EXPLAIN plans, plus interview-style worked exercises.
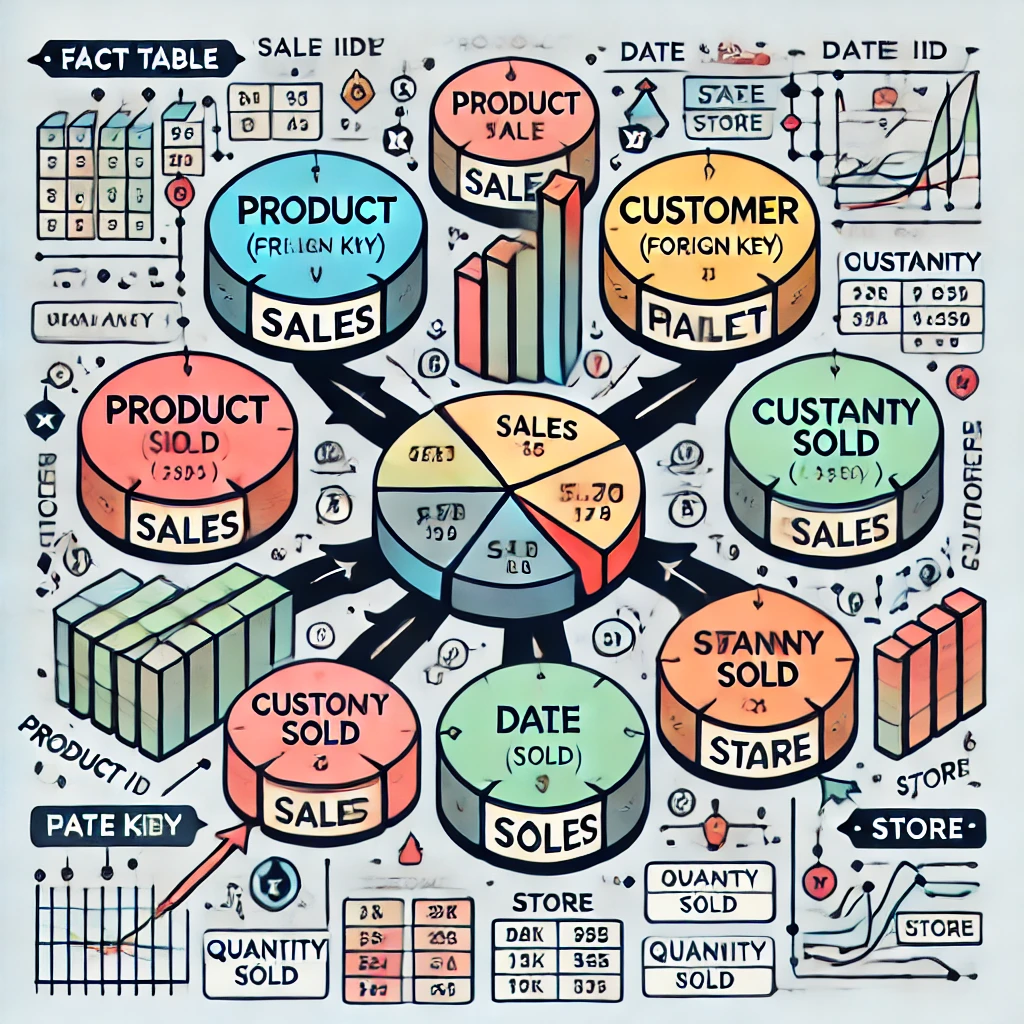
RDBMS fundamentals, star/snowflake/galaxy schemas, and Kimball dimensional modeling — bus matrix, conformed dimensions, and a worked sales model.
The full non-relational landscape — in-memory (Redis), documents (MongoDB), wide-column (Cassandra), key-value (etcd, RocksDB), graph (Neo4j, Neptune), time-series, and search.
ETL and ELT patterns, large-scale ingestion, Apache NiFi flows, Kafka streaming, and Parquet columnar storage — the data movement layer.
Open table formats (Hudi, Iceberg, Delta), catalogs (Polaris, Unity, Nessie), and query engines (Trino, StarRocks) — the open lakehouse stack.
pgvector, Chroma, Weaviate, FAISS — embeddings, ANN indexes (HNSW, IVF, PQ), and the retrieval layer behind RAG and semantic search.
The rest of this page is a one-screen quick reference. For depth, follow the cards above into the section landing pages and their per-topic deep dives.