Graph databases treat relationships as first-class citizens: nodes and edges are stored natively, traversals run in constant time per hop, and multi-hop queries beat recursive SQL by orders of magnitude. Reach for them when the relationships are the data — social graphs, fraud rings, knowledge graphs, dependency maps, identity and access trees. For non-graph NoSQL engines (document, key-value, wide-column, time-series, search), see NoSQL Databases.
Two production graph engines compared: Neo4j’s Cypher property-graph model versus ArangoDB’s multi-model approach — with traversal patterns and query semantics.
AWS managed graph DB — Gremlin and openCypher (property-graph) plus SPARQL (RDF). Includes Neptune ML for GNN training and Neptune Analytics for whole-graph algorithms.
Distributed graph on Cassandra / ScyllaDB / HBase, indexed via Elasticsearch. Speaks Apache TinkerPop’s Gremlin. The standard choice when Neo4j scale isn’t enough.
Distributed native graph DB in Go — predicate sharding, GraphQL-first API, ACID transactions across the whole graph. Built on BadgerDB.
The non-graph NoSQL landscape — in-memory caches, document stores, wide-column tables, key-value engines, time-series, and search. Pick by access pattern.
GraphQL the query language — typed schema, single endpoint, client-driven field selection. An API spec, often paired with graph or relational backends. Don’t confuse it with graph databases.
Specialized similarity-search databases for embeddings. Often paired with knowledge graphs in modern RAG systems — embeddings retrieve, graphs traverse and reason.
Pure-Go LSM key-value store — the storage layer underneath Dgraph. WiscKey value separation, ACID transactions.
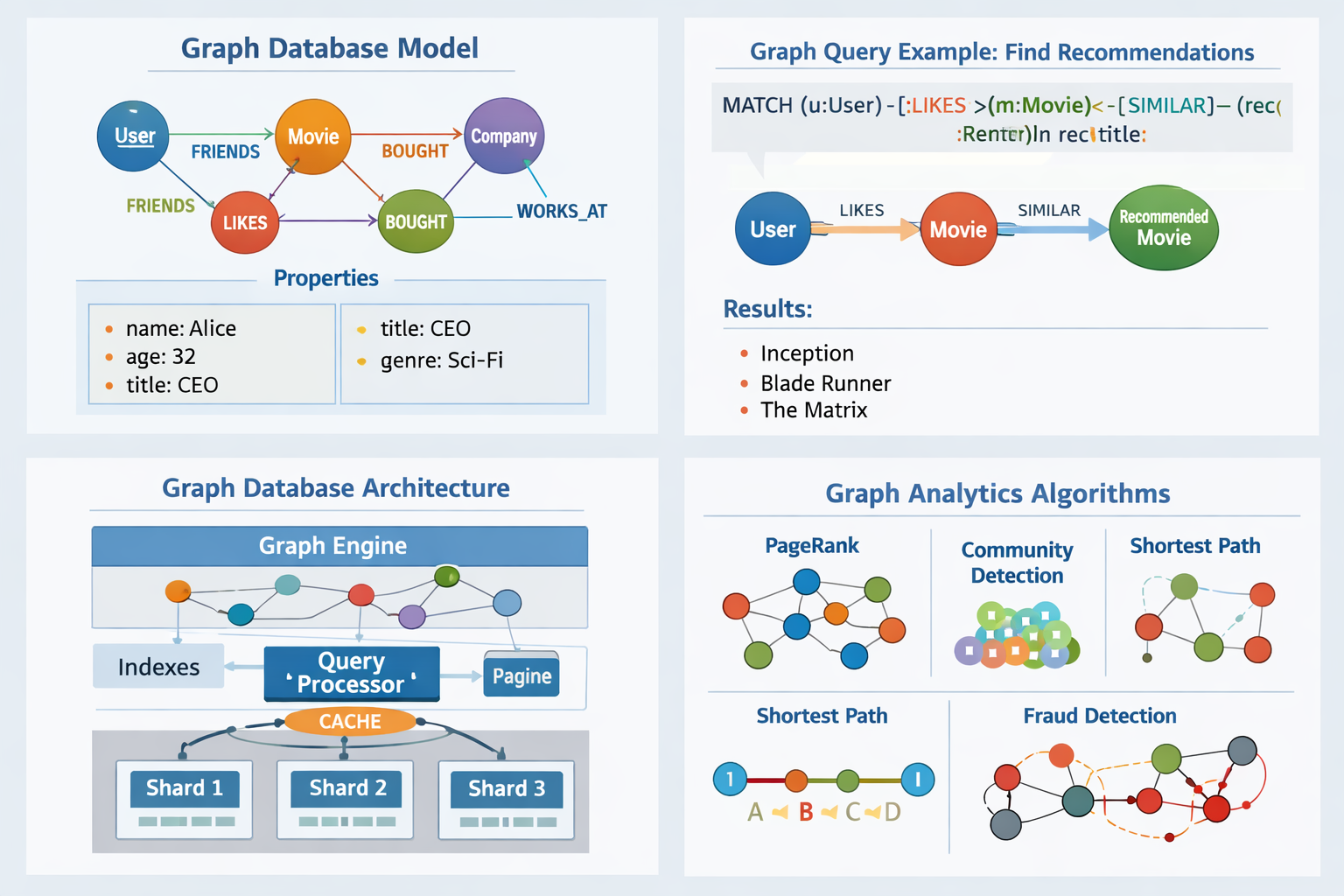
A graph database is a database system designed to store, manage, and query data as a graph structure. It emphasizes relationships between entities as first-class citizens, rather than treating relationships as secondary constructs (such as foreign keys).
Graph databases are optimized for relationship traversal, pattern matching, and connected-data queries.
Common usage: social networks, fraud detection, recommendations
Common usage: knowledge graphs, semantic web, linked data
Indexes accelerate entry points, while traversals dominate query execution time.
Most production graph databases support full transactional guarantees.
Graph databases are most effective when relationships are the data, not just attributes.
These platforms represent the most commonly used graph databases across enterprise systems, open-source ecosystems, real-time applications, semantic technologies, and cloud-native architectures.
Twelve hand-picked talks and tutorials covering each engine on this page, plus the foundational graph-DB concepts behind them. Click any thumbnail to play in place. Roughly grouped: foundations + Neo4j (row 1), ArangoDB + Amazon Neptune intros (row 2), Neptune deep dive + JanusGraph + Dgraph (row 3).
Neo4j — Ten-minute primer on nodes, edges, and why traversal beats recursive joins. The fastest way into section 2.1.

Fireship — Whirlwind 100-second tour of Neo4j and the property-graph model. A pre-flight check before the longer tutorials below.

freeCodeCamp.org — Long-form Neo4j course covering install, the browser, Cypher patterns, and graph modeling. Pairs with sections 2–4.

Neo4j — Official walkthrough of Cypher's ASCII-art pattern syntax. Maps directly to section 2.3.1 (Cypher).

LearnCode.academy — Beginner-friendly tour of ArangoDB's multi-model approach (graph + document + key-value) and AQL. Sets up the ArangoDB card above.

Arango (official) — Why one engine for graph, document, and key-value beats stitching three together. Background for section 2.2.3 (LPG) and the Neo4j vs. ArangoDB comparison page.

Amazon Web Services — Official intro to Neptune — Gremlin, openCypher, and SPARQL on one managed service. Pairs with the Amazon Neptune card.

AWS Developers — Virtual workshop combining graph-DB fundamentals with a Neptune deep dive and live demo. Bridges sections 2 and the Neptune deep dive page.

AWS Events — re:Invent 2020 deep dive on Neptune internals: storage, replication, query optimization. Reference for Neptune ML and Neptune Analytics.

The Linux Foundation — Jason Plurad (IBM) on JanusGraph's pluggable storage (Cassandra / HBase / ScyllaDB) and TinkerPop Gremlin. Maps to the JanusGraph card.

Fireship — 100-second intro to Dgraph — predicate sharding, GraphQL-first, written in Go. Pairs with the Dgraph card.

Singapore Gophers — GopherCon SG 2017 talk on Dgraph's architecture, distributed transactions, and the BadgerDB storage layer. The detailed companion to the Fireship clip.